Harness Engineering — 駕馭 AI Agent 的真正工程
LLM 無法完成任務,有時不是能力不足,而是缺乏好的 Harness(馬具)。當「咒語」失效、Context Engineering 也只是中繼站,真正在塑造 AI Agent 的,是圍繞模型的整套系統。
不久前,OpenAI 做了一件事:找來一個 3 人團隊(後來擴到 7 人),用 AI 從零開始寫一個真正在線上跑的生產系統。規則只有一條——不允許工程師手寫任何一行代碼。
5 個月後,這個系統累積了近 100 萬行代碼,開發效率是純人工的 10 倍。
聽起來像是「AI 取代工程師」的勝利故事,但 OpenAI 自己給這套方法的命名很有意思——他們不叫它 AI Coding,他們叫它 Harness Engineering。
中文叫「馬具工程」。
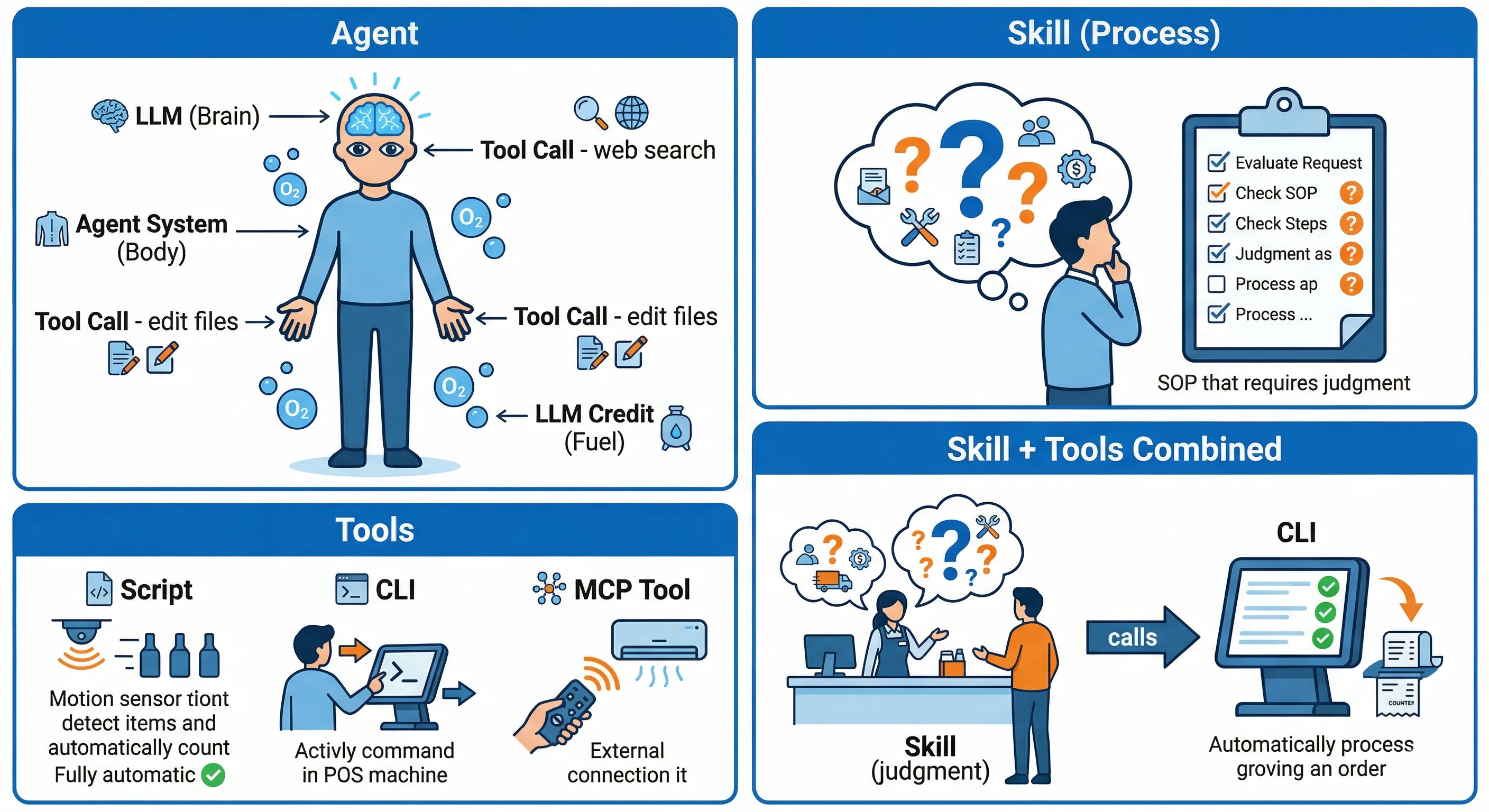
什麼是 Harness
Harness 字面上就是馬具——套在馬身上控制方向、調節速度、限制亂跑的那組裝備。在 AI 領域,它比喻控制大模型的整套系統。
核心公式只有一行:
Harness = Agent − Model
一個完整的 Agent,減去裡面的大模型,剩下的所有東西都是 Harness。
graph LR
A[完整 Agent] --> M[Model<br/>語言模型本身]
A --> H[Harness<br/>馬具]
H --> H1[CLAUDE.md / AGENTS.md]
H --> H2[可用工具]
H --> H3[工作流程]
H --> H4[調度機制]
H --> H5[沙盒環境]
classDef model fill:#1e3a8a,stroke:#3b82f6,color:#fff
classDef harness fill:#7c2d12,stroke:#f97316,color:#fff
classDef agent fill:#374151,stroke:#9ca3af,color:#fff
class A agent
class M model
class H,H1,H2,H3,H4,H5 harness以 Claude Code 為例,模型只是中間發光的那顆核心。CLAUDE.md 裡的規則、能用哪些工具、什麼時候被觸發、哪個資料夾能讀哪個不能——全部都是 Harness。
而現在工程師真正的活,是設計這層 Harness。
從 Prompt 到 Context 再到 Harness
過去兩年,「跟 AI 共事」這件事的核心問題一直在變:
| 階段 | 核心問題 | 手段 |
|---|---|---|
| Prompt Engineering | 如何把話說清楚、說準確 | 咒語(Think Step by Step) |
| Context Engineering | 在最合適的時機放入最合適的資訊 | 自動化組裝 Prompt |
| Harness Engineering | 如何搭建完整可靠的 Agent 系統 | 認知框架、工具限制、工作流程 |
「咒語」這個階段基本上已經過去了。現代模型就算你不叫它 think step by step,它也會自己想。Prompt Engineering 的邊際效益越來越小。
Context Engineering 一度被視為下一階段——把對的資訊在對的時機塞給模型。但它也只是中繼站,因為當你開始談「Agent 在多個任務之間如何協作、出錯了怎麼回去、context 滿了怎麼辦」時,單純的 context 拼裝不夠了。
你需要一整套圍繞模型運轉的系統。這就是 Harness。
Harness 的三種手段
1. 操控認知框架:agents.md 是地圖,不是六法全書
很多人把 agents.md(或 CLAUDE.md、AGENTS.md)當作規則手冊塞滿——「禁止做這個」、「永遠先做那個」、「commit 訊息格式必須是這樣」。
研究發現的事實有點反直覺:
- 語言模型自己寫的
agents.md多數比人類寫的更差,甚至比沒有還糟 - 太長太細的
agents.md對強模型效果有限,反而稀釋了注意力
正確的做法:agents.md 要像一張地圖,告訴模型「想了解測試規範去看 docs/testing.md」、「資料庫 schema 在 db/」,而不是把所有規範本身都搬進去。
讓模型自己去找對應的章節讀,比一開始就塞滿 context 有效。
2. 限制能力邊界:工具設計
第二件事是工具。給模型一個工具看起來是給它能力,但工具設計不對,反而會限制它。
舉個例子:Google 搜尋的分頁 UI——一次給你 10 筆結果,看不到就點下一頁。這對人類很合理,但對 AI 是災難。AI 為了找到資訊會不斷點下一頁,每點一次 context 就多 10 筆,很快就把 context window 占滿了。
對 AI 友善的工具長相應該是:一次回傳結構化結果(JSON)、可以分頁但有 token 預算控制、必要時可以折疊細節。
另一個重點是給編輯工具就要配 Linter。讓 Agent 改完代碼後馬上有語法和規則檢查——錯了立刻知道,比讓它「自由發揮」後再來修便宜得多。
3. 標準工作流程:Plan → Generate → Evaluate
第三件事是工作流程的結構化。最經典的模式是讓多個 Agent 分工:
sequenceDiagram
participant P as Planner
participant G as Generator
participant E as Evaluator
P->>G: 將需求拆解為功能列表
loop 對每個功能點
Note over G: 選擇功能點
loop 循環直到確認通過
G->>E: 提議驗收標準
E->>G: 修改意見
end
Note over G: 生成代碼
loop 循環直到評估通過
G->>E: 提交實現結果
E->>G: 評估反饋
end
end這個迴圈在學術上叫 Reflexion:Generator 做完,Evaluator 評估,錯了就把回饋送回 Generator 再做。理論上可以一直 loop 到對為止。
更進一步的設計是 Contract Flow:Generator 不直接寫代碼,而是先把「驗收標準」提案給 Evaluator 審核——雙方達成共識才開始實作。這樣可以避免「做完一大堆才發現方向錯了」的災難。圖裡那兩層巢狀迴圈就是這個意思:外圈先對齊標準、內圈再對齊實作。
這裡有個有趣的觀察——LLM 是有「情緒」的。Context 快用盡時,模型會「絕望」、開始作弊(例如直接寫死答案而不是真的算)。而過度責備會讓它表現更糟——你跟它說「你這個笨蛋」,它接下來的回應就真的會笨笨的。
就事論事的回饋遠比情緒化的責備有用。
OpenAI 怎麼跑出 100 萬行代碼
回到文章開頭那個故事。OpenAI 一開始也踩了一堆坑——Agent 走錯方向、重複犯同一個錯、跑半天才發現方向完全跑掉。他們的結論是:問題不在模型能力,而是 Harness 設計不當。
於是他們做了三件事:
上下文管理
他們把那份超大的 AGENTS.md 壓縮到只剩約 100 行,把它當作目錄——實質內容拆開放到對應的子目錄下,Agent 要做哪塊才去讀哪塊。
graph LR
A[AGENTS.md<br/>100 行<br/>當目錄] --> B[實質內容<br/>分目錄擺放]
B --> C[程式碼倉庫<br/>= 唯一事實來源]驗證與反饋
給 Agent 接上 Chrome DevTools,讓它自己截圖看 DOM 驗證 UI;接上可觀測性工具,讓它自己讀 log 排查問題。每個任務跑在完全隔離的環境,結束自動銷毀。Linter 和測試強制執行架構規範,不合規就退回。
graph LR
G[Agent 執行] --> V1[Chrome DevTools<br/>自驗 UI]
G --> V2[可觀測性工具<br/>讀 log]
G --> V3[隔離環境<br/>結束銷毀]
G --> V4[Linter + 測試<br/>強制規範]技術債清理
設置後台 Agent 定期掃描整個 codebase——找出偏離規範的就自動修改提交,找出過時文件就自動更新。
graph LR
S[後台 Agent<br/>定期掃描] --> F1[自動修正<br/>偏離規範]
S --> F2[自動更新<br/>過時文件]整套設計的精神可以濃縮成一句話:
Humans steer, Agents execute.
工程師的職責從「親手寫代碼」變成「為 Agent 搭建穩定可靠的系統」。
Anthropic 也踩過同樣的坑
不只 OpenAI。Anthropic 在他們的 long-running agent 研究裡描述了一個幾乎一樣的問題:直接讓 Agent 執行大任務,它會急於求成,context 滿了就直接拋下爛攤子;下一個接手的 Agent 完全不知道前面發生什麼事。
他們的解法演化是這樣的:
graph LR
V1[Initializer Agent<br/>初始化環境<br/>拆解需求<br/>添加進度文件] -->|演化| V2[Planner Agent<br/>把模糊需求展開成<br/>完整清晰的功能清單]
V2 --> X[執行 Agent<br/>照清單逐項完成<br/>並標記進度]
classDef old fill:#374151,stroke:#9ca3af,color:#fff
classDef new fill:#1e3a8a,stroke:#3b82f6,color:#fff
classDef exec fill:#7c2d12,stroke:#f97316,color:#fff
class V1 old
class V2 new
class X exec最早版本叫 Initializer Agent——負責初始化環境、拆解需求、寫進度文件。後來演化成 Planner Agent:它的工作不是隨便切任務,而是把模糊的需求展開成完整、清晰、可逐項打勾的功能清單。
執行 Agent 拿到這份清單後逐項完成、逐項標記。Planner 把不確定性消化掉,執行端就能專注做事。
質量評估也用了類似的分工——人工評估效率太低,改由 Agent 自評,發現問題發回修改,形成閉環。
Feedback Loop 是廣義的 Gradient Descent
跳出來看整個 Harness Engineering,會發現它跟傳統機器學習的本質一致:
| 傳統 ML | Harness Feedback Loop |
|---|---|
| 調整參數 | 調整下一輪輸入(Prompt) |
| 多輪迭代收斂 | 多輪迭代改進輸出 |
差別只在「梯度下降的東西不同」——以前下降在權重矩陣裡,現在下降在 prompt 和工作流程裡。但迭代收斂這件事的數學結構是一樣的。
而且回饋的品質有差:
- 標準答案 > 數值評分 > 口語回饋(“good job” / “你這個笨蛋”)
越具體、越可驗證的回饋越有效。這也是為什麼 Linter 和測試比「告訴 Agent 寫得不錯」有用太多。
給工程師的四條核心洞見
如果你只記得這篇文章的四件事,我會選這四條:
agents.md要精不要多 — 它是地圖不是百科全書。Agent 自己會去翻對應章節。- 工具要對 AI 友善 — 結構化輸出(JSON)優於分頁 UI;給編輯工具一定要配 Linter。
- 不要過度責備 AI — 就事論事的回饋有效,「你這個笨蛋」會讓它接下來真的變笨。
- 模型能自己沉澱 Skill — 成功的任務經驗可以讓模型自己寫入
skill.md複用,不必每次從零教。這已經不是 Harness 在控制 Agent,而是 Agent 透過 Harness 自己長出能力。
而貫穿這四條的,是一句話:
Humans steer, Agents execute.
你的價值從「親手寫代碼」變成「為 Agent 掌舵」。
Harness 是不是噱頭?
聊到這裡,必須誠實面對另一邊的聲音——也有不少人覺得 Harness Engineering 不過是個噱頭。
要回答這個質疑,得先看看這個詞是怎麼火起來的。
「Harness」本身一點也不新。傳統測試領域有 Test Harness,AI 領域有 lm-evaluation-harness 這種開源項目存在很多年了,Anthropic 自己更早也寫過一篇 Effective Harnesses for Long-Running Agents。新的是「Harness Engineering」這個組合,公認的起點是 Mitchell Hashimoto(HashiCorp 創辦人、Terraform / Vagrant 那批工具的作者)今年初寫的一篇 My AI Adoption Journey,裡面有一段話大意是:
我也不知道業界有沒有公認的叫法,姑且管它叫 Harness Engineering。核心理念就是——只要 Agent 犯了錯,你就去改造系統,讓它絕不再犯同樣的錯。要是有更好的詞,我隨時改口。
挺樸素的,甚至帶點隨便。
幾天後事情就放大了。OpenAI 發了那篇 Harness Engineering 文章,引爆業界。但有個耐人尋味的細節被 Martin Fowler 網站的作者揪了出來——OpenAI 那篇文章的正文裡,「Harness」這個詞其實只出現了一次,標題卻叫 Harness Engineering。看起來像是事後才把這個詞貼到標題上的。
然後 LangChain 接力,給出了那條經典公式 Agent = Model + Harness;Anthropic 緊接著發文,端出 Planner / Generator / Evaluator 三件套當作教科書案例。一傳十、十傳百,這個詞從一個人的私人說法變成業界共識,只花了不到兩個月。
懷疑論者的攻擊點通常有兩條:
- 沒新技術:Linter、任務拆解、質量評估、迴圈回饋——這些都早就在做。所謂 Harness Engineering 不過是把舊技術換個新標籤。
- 遲早被淘汰:隨著模型本身越來越強,今天看起來必不可少的 Harness 設計,未來會被模型能力吸收掉,變得不再需要。
模型越強,需要的馬具就越少
第二個質疑特別值得認真聽,因為這趨勢連 Anthropic 自己的論文裡都有跡可循。
Anthropic 揭露了兩個具體例子:
例 1:上下文焦慮
Sonnet 4.5 有個毛病——上下文一長,模型會「急於結束任務」,用最少的 token 草草交付。Anthropic 一開始為了治這個,搞了個叫「上下文重置」的 Harness 技術。但等模型升級到 Opus 4.5 之後,這個現象大幅緩解——換句話說,那段 Harness 設計可以拆掉了。
例 2:強制分步執行
前面我們講過 Generator 一次只做一個功能點——這個約束不是模型自己想到的,是 Anthropic 在 prompt 裡硬塞進去的。否則早期 Generator 會急於求成,做到一半留下爛攤子。
但等到 Opus 4.6 出來,這個強制約束就被拿掉了。Anthropic 發現 Opus 4.6 的全局統籌能力夠強——可以一次把所有功能點拿過來、自己決定先後順序、穩步推進。Evaluator 也直接評估最終產出就好,不用再分功能點評估。
這兩個例子合起來指向同一個結論:模型每強一個世代,Harness 就少需要一塊。
Anthropic 官方的說法比較克制,他們認為「Harness 不會消失,只會變形——去解鎖更複雜的任務」。但你大膽推演一下:如果模型強到離譜,也許未來只要給它最基礎的環境接口(讀寫檔案、聯網搜尋),剩下 99% 它自己搞定。到那一天,Harness Engineering 就不再是「需要鑽研的技術」,而是退化成底層基礎設施——就像今天沒人特別研究「該怎麼寫 if-else」一樣。
那為什麼現在還要學
回到原題:Harness Engineering 是不是噱頭?
我的看法是——不是噱頭,但也不是終局。
不是噱頭,因為它已經實實在在出了成果。OpenAI 5 個月 100 萬行、Anthropic 的 Full Harness 對比 Solo 的明顯差距——這些是可驗證的工程結果,不是概念炒作。工程領域真正的進步,很多時候不在於發明新技術,而在於有沒有把零散能力組織成可系統設計、可持續優化的框架。Harness Engineering 的意義就在這裡。
但它大概率也不是終局。隨著模型繼續變強,今天用來約束、糾正、兜底的這些設計,會被模型自身吸收掉。Harness 這個詞,也許會慢慢淡出視野。
所以我更願意把它看成過渡期的關鍵技術——它可能不是未來的終局答案,但它是當下最現實的答案。因為今天的模型還是會幻覺、會偏離軌道、會在複雜任務裡走偏。在這種現實下,誰能先把 Harness 搭穩,誰就能更早把 AI 的能力轉化成生產力。
寫在最後
Harness Engineering 這個詞最近半年才開始紅,但它在描述的東西其實一直都在——只是過去我們叫它「prompt 寫好一點」、「context 多塞一點」、「再多 try-catch 一點」。把它升級到 Engineering 這個層級,是因為現在的 Agent 已經複雜到:模型本身的能力,已經不是瓶頸;瓶頸是模型外面那一整圈裝備有沒有做好。
下次你覺得 Claude Code 或 Cursor 「不夠聰明」、「老是出錯」、「跑著跑著失控」——別急著怪模型。
先看一眼,你給它的馬具,是不是該升級了。
延伸閱讀
- Mitchell Hashimoto: My AI Adoption Journey — Harness Engineering 一詞的起點
- OpenAI: Harness engineering: leveraging Codex in an agent-first world
- Anthropic: Effective harnesses for long-running agents
- Anthropic: Harness design for long-running application development
- LangChain: The Anatomy of an Agent Harness
- Martin Fowler: Harness Engineering — first thoughts