Database Sharding 概念

筆記一下 Database Sharding 概念
為什麼需要 DB Sharding?
在海量資料的儲存情境下,DB 的效能會受到影響,透過垂直擴充架構無法滿足,因此需要資料分片(shard),以水平擴展的方式來提升效能。
DB 水平擴展
分為 Horizontal Partitioning 與 Sharding,前者是在同一資料庫中將 table 拆成數個小 table,後者是將 table 放到數個資料庫中。
Horizontal Partitioning 的 table 與 schema 可能會改變,而 Sharding 的 schema 則是相同,但分散在不同資料庫中。
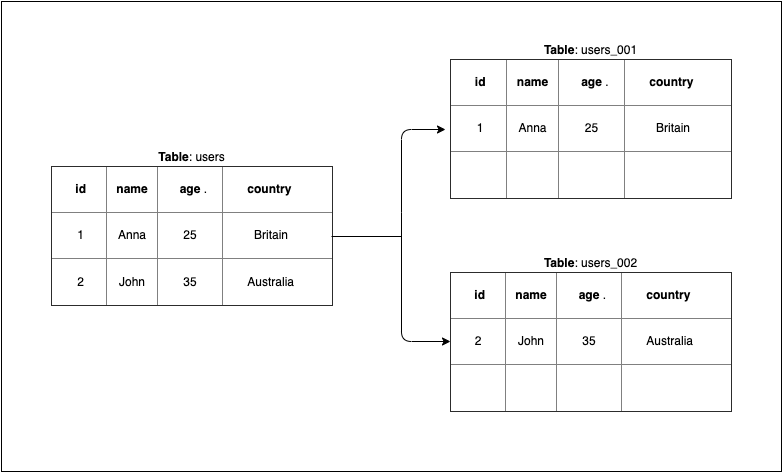
Sharding,右邊兩個 table 會儲存在不同的資料庫中
Sharding 的方式
常見的 Sharding 方式有以下:
- Range-based partitioning
- Hash partitioning
Range-based partitioning
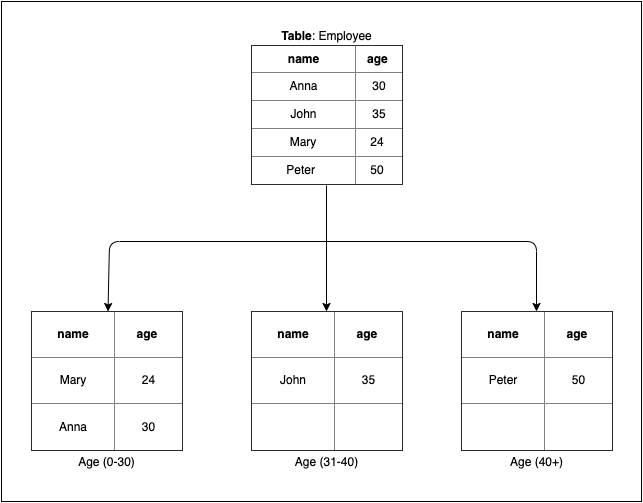
會根據某個 key 的範圍分區,key 的選擇非常重要,如果選擇不好,將會有分佈不均勻的問題,以上圖為例,年齡分為 0-30、30-40、>40,將會個別存在於不同資料庫。
Hash partitioning
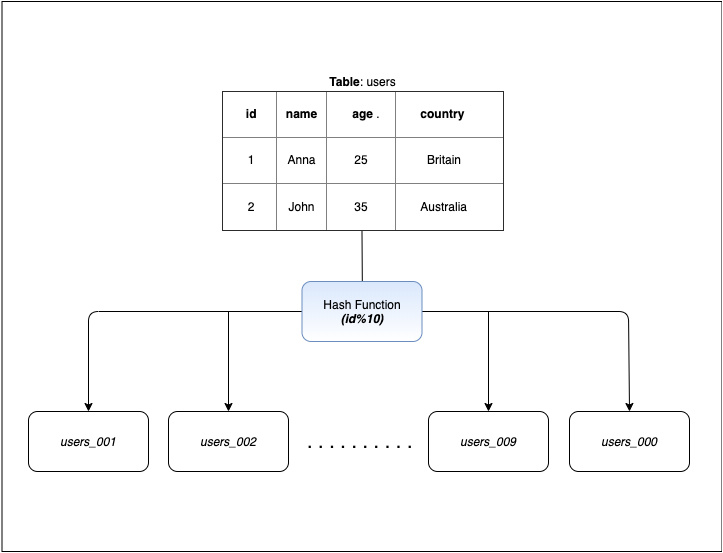
將特定的 key (例如:id) 丟到 hash function 中,得出要存取的目標資料庫,hash function 必須確保資料在分區中均勻分佈。
如何實現 Sharding?
有兩種方式可以實現 Sharding:
- Client-side partitioning
- Proxy-assisted partitioning
Client-side partitioning
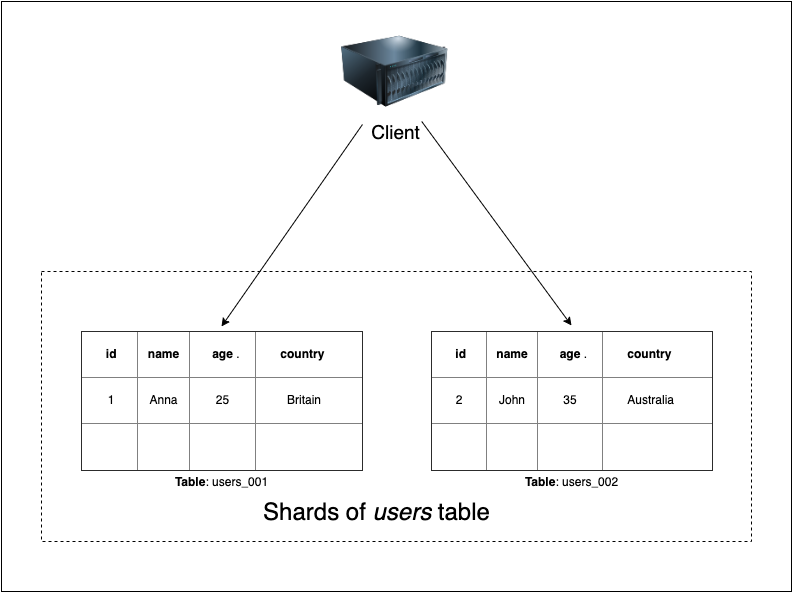
Client-side 知道資料怎麼分區,直接選擇分區來讀寫資料。
優點:
- 沒有中間層
缺點:
- 實現後分區數不容易更改,因為所有 Client-side 程式碼都需要做調整
Proxy-assisted partitioning
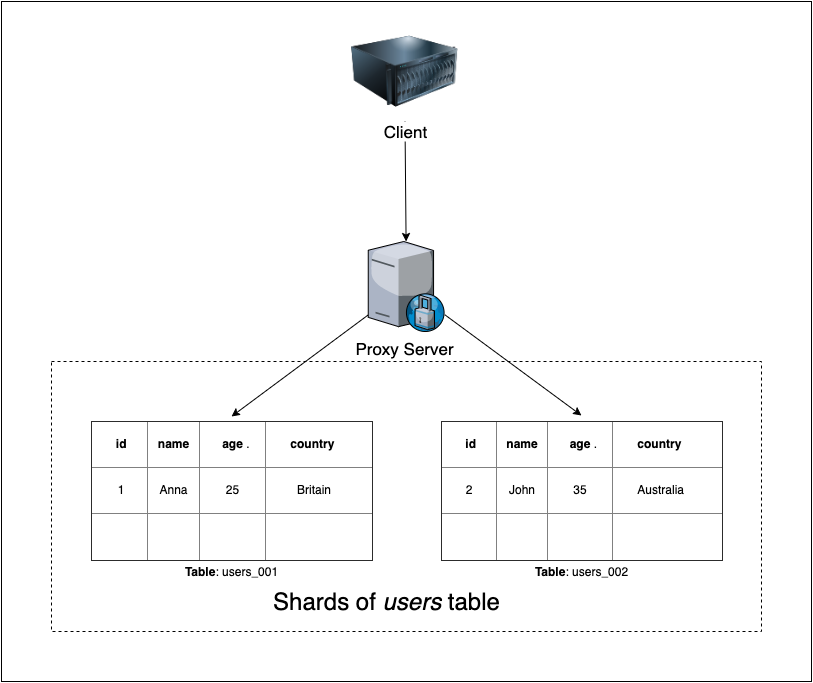
Client-side 不是直接調用分區,而是向 Proxy server 發出請求,Proxy server 根據分區的方式將請求轉發到正確的資料庫。
優點是 Client-side 不用知道任何關於 Sharding 的邏輯,並且可以比 Client-side partitioning 更容易地更改分區和數量。
結論
對於海量數據的資料庫,Sharding 是一個很好的解決方案,有助於將負載從單個拆分到多個節點,但是,他也給應用程式增加了很多複雜性。